DataBin converts text data files into binary number files that can be imported into Sequencer and Array modules.
DataBin reads just about any text based data file with numbers in any range. Once the source data file is read into the text window, you can pick whether to convert all numbers, or select a field and convert just the numbers in that field. The valus you select are charted in the graphical display window, to give you a quick idea of the data's shape. You can save it as a binary file with the data normalized to the 0-127 MIDI range, or as the original values in either floating point or ArtWonk sequencer/array format.
To use DataBin, you read in a data file, trim it to size if you like, set whether to convert all numbers, numbers in a comma delimited field, or numbers in a character position column. Then you click the Convert button to convert the data and see it plotted in the graph area below the text window. If you are happy with the selection, you can then click on Save to save the data to a binary (.bin) file.
With creative mapping of your data not only for pitch but also using it to affect other MIDI parameters such as Volume, Modulation, Pan, etc., you will discover data sonification can produce highly listenable music - music that has extra layers of depth created from the real-world data you have chosen to sonify.
Data Files:Data files must be ASCII/ANSI text. If you can read it in NotePad it will be OK. Other than that, there are very few limitations. If you read a file that is not text, or that has no line feed characters in it to separate the lines, it will appear as unreadable garbage or as an empty page. This is your clue that the data file format is not useable by DataBin.
Some data files are very large - up to several megabytes. You can read and process these, but it will take extra time. Usually it will be better to break up these huge files into smaller ones, but there is no requirement to do so.
Opening a Data File:To load a data file, click on the Open button, and open the file with the standard file pop up window that will appear. DataBin treats the source data file as Read Only. That is, it never alters the source data file. If you make any changes, they only affect a temporary copy. The original files will not be altered.
Some data files are stored in Unix format, but other than taking a little longer to read, this will be transparent to you, as the software automatically translates Unix files. The translated file is saved in a temporary file ("temp.$$$") which can be ignored , as it will be changed every time a new Unix file is read.
Data File Format:DataBin can process three file formats. Free numbers, comma delimited numbers, and numbers arranged in columns. You will recognize these formats instantly when you load the file. Comma delimited format has lines of information separated by commas; column data shows up as neatly arranged columns of numbers and other data; and everything else can be considered free numbers.
The main difference between free numbers and the other two formats is that free numbers (selected by default with the "All Nums" option) processes everything that is a number, line by line, top to bottom. The other two options ("Commas" and "Columns") only process the numbers in the selected fields.
Setting Comment Characters:If the first character of a line is a comment character, as placed in the "Comment" box just under the Open button, the line is ignored and no numbers on that line will be processed. Since "#" is commonly used for comments, it is the default comment character, but you can type in any characters you like. As long as the first character of a line is one of the characters in the comment box, the line will be ignored.
Selecting a Field to Process:All Nums - the default selection - needs no further selection. You can immediately click on the Convert button, and all numbers in the file not on comment lines will be converted, and you will see a graph of the results. The other two selections, Commas and Columns, require you to select which field to process.
When you click on the Commas option, one of the two input boxes just below the options will become active, for you to type in the field number you want to process. Data fields are numbered left to right, starting with 1. You don't actually have to count which field you want - instead you can just put the cursor on one of the numbers, and then click on the Set button. The field number the cursor is positioned over is entered into the box. At this point you can click on the Convert button, and the numbers in that field in all the lines will be processed and you will see a graph of the results.
If the source data is in columns, click on the Columns option. Both of the input boxes below the options will become active. Type in the column number in the first box. This is the character number (starting with 1) that the column starts on . And type in the number of characters in the field in the second box. Or you can do it the easy way: Just highlight one of the numbers in the text, making sure to include all of the text area that make up the column, and click on the Set button as before. The input boxes will be filled in with the starting column of the highlighted text and the length of the highlight. At this point you can click on the Convert button to process and display the graph.
Trimming the Data File:To limit the amount of data to process, you can trim the data file. The Del Above button deletes all lines above the current line, which is the line the cursor is on. The Del Below button deletes all lines below the current line, and Del Line deletes the current line. Remember, the data file itself is never altered. These buttons just delete the lines to be processed. To restore deleted lines, simply click on the Open button and reload the file.
How Data is Processed:When you click on the Convert button, the numbers are collected from the data file and stored as an array of double precision floating point numbers. All processing up to the final conversion to MIDI integers is in double precision floating point, to maximize the accuracy of the data translation. When you choose to save the data as floating point or ArtWonk sequencer files, the converted floating point data is saved as the original numerical values.
Processing with Byte option, for MIDI:
When you choose to save the data as Bytes (actually the MIDI byte range of 0-127) the numbers are tested to see if any of them are negative. If they are, an offset is added to all numbers to make them all positive. The value of the offset is the absolute value of the smallest (most negative) number, so this least value becomes 0, and all other values are adjusted upward.
If there were no negative numbers and if the Trim check box is checked (the default), then the value of the lowest positive number is subtracted from all numbers, making the lowest number 0, with all other values adjusted upward.
If the Normalize check box is checked (the default), the highest value number is divided into 127, then all numbers are multiplied by this value. This normalizes all numbers to the legal MIDI range of 0-127. That is, if the number range was higher than 127, the numbers are compressed, if the range was less than 127, they are expanded. The only time you would not normalize values is if the number range is below 127, and you want to use the unmodified values.
Finally, all numbers are limit tested to insure none are below 0 or greater than 127. Numbers below 0 are set to 0, numbers greater than 127 are set to 127; after this is done, the numbers are converted from double precision floating point to byte integers, and they are stored in a byte array ready to be saved in a .bin file. Click on the Save button for the save file pop up window, to name and save the file.
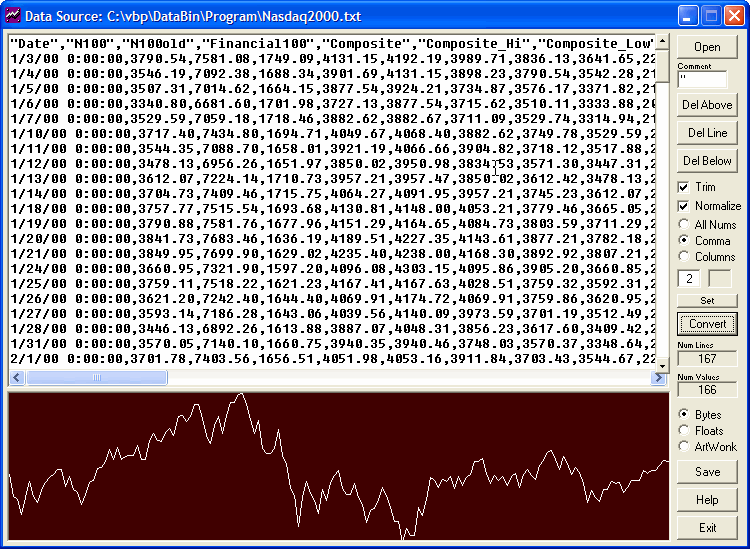
Mini Tutorial:There is an example data file included with this program, that we will use for this mini tutorial. It is the NASDAQ daily averages for several stock categories over the first half of year 2000. This file came from the NASDAQ website, where you can download daily averages from 1971 to the present.
Start by running DataBin, and opening the file "Nasdaq2000.txt" from the program directory. You will see a very dense page of text, and if you look closely you will see that the fields are separated by commas.
Notice the top line is a label line. It has the same fields, but they contain text:
"Date","N100","N100old","Financial100","Composite",etc...
Then the lines following have the actual data:
1/3/00 0:00:00,3790.54,7581.08,1749.09,4131.15,etc...
Since we don't want to process the label line, it can be ignored by typing the quote (") character into the Comment box. The quotation mark ("Date"...) is the first character of the line, so even though it wasn't intended as a comment character, it works fine as one anyway.
Click on the Comma option box. The first of the two text entry boxes below becomes active. This box gets the field number of the one you want to capture. The easiest way to do this is to go to the top line and click on the name of the field., then click on the Set button. Then click on the Convert button to convert the data and see it displayed as a graph below the text window.
You can elect to Save the data for use with a Sequencer or Array module by selecting one of the three output formats, Bytes, Floats or ArtWonk. Use Bytes or Floats if you are using other software to read your data, and the ArtWonk (.awa) format for use within ArtWonk or MusicWonk. To load the data into a Sequencer or Array module click on the blue Properties button in the upper right of the module and click on the File Load button if the data is in .awa format, or Import if it is in binary or floating point format.
Copyright © 2000-2010 by John Dunn and Algorithmic Arts. All Rights Reserved.